

ML Engineering
مساله تشخیص محصولات باسلام؛ یک تجربه عملی از بهکارگیری LLM ها
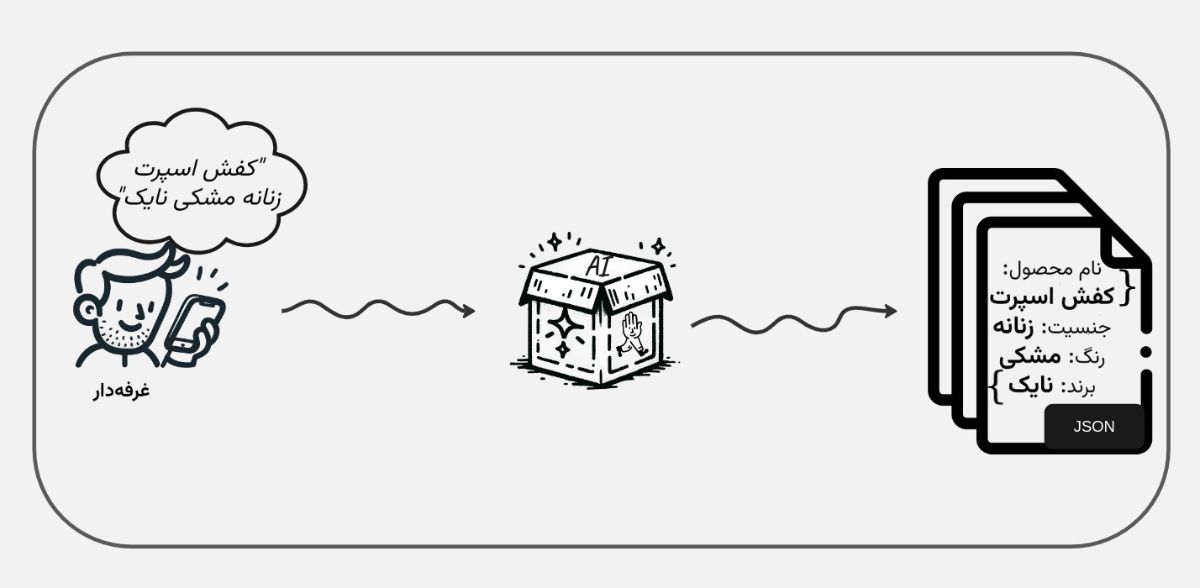
یکی از پرچالشترین و مهمترین مسائلی که در چند سال اخیر، ما در تیم هوشمصنوعی باسلام باهاش مواجه بودیم مساله دستهبندی و تشخیص محصولات بود. در این سالها کارهای زیادی برای حل بهتر و دقیقتر این مساله انجام شد ولی خب همچنان تمام نیازهای ما رو پوشش نمیداد. تا اینکه سال قبل تصمیم گرفتیم این مساله رو این بار بصورت ریشهای و با چارچوبی جدید حل کنیم؛ که چنین تصمیمی، ما رو به سمت ماجراهایی سوق داد که سر از LLM ها درآوردیم. در این بلاگ سعی شده به تجربهی حل مساله دستهبندی با کمک LLM ها بپردازیم و مباحث فنی این مساله رو بررسی کنیم. از اونجا که این پروژه کاربرد عمومی داره و هر پلتفرمی میتونه ازش استفاده کنه، ما کد و مدلها (ورژن یک و دو) و دیتاستها (ورژن یک و دو) و خلاصه هر آنچه که مربوط به این پروژه بوده رو اوپن کردیم و برای علاقهمندان در دسترسه. در بخش آخر بلاگ هم، قدمهایی که در آینده باید برداریم رو شفاف کردیم تا کسانی که دوست دارند با حل این مسائل به رونق بیشتر بازار کسبوکارهای آنلاین کمک کنند و همقدم ما بشوند رو پیدا کنیم و دست گرمشون برای همکاری بفشاریم.
شرح مساله؛ چالش دستهبندی محصولات در باسلام
تو «باسلام» ما با یک واقعیتی مواجه هستیم که همزمان هم شیرین و هم تلخه و اون اینکه باسلام پلتفرم بزرگیه و تنوع محصولاتش بالاست. از عسل تا صفحه خورشیدی، از لباس و اکسسوری تا مبلمان و لوازم خانگی، از تجهیزات کوهنوردی تا کتاب و محصولات فرهنگی و خلاصه از شیر مرغ تا جون آدمیزاد همگی در این پلتفرم پیدا میشه. و همه این محصولات رو خود غرفهدارها اضافه میکنن، نه ما! از این جهت شیرین که برای ما فعالان حوزه AI چیزی بیشتر از حجم دادهی زیاد خوشحالمون نمیکنه و از این جهت تلخ که حجم داده بالا، با خودش پیچیدگی مسائل رو هم بههمراه داره :)
در چنین پلتفرمی که الان بیش از ۱۴ میلیون محصول داره و روزانه بیش از ۱۵ هزار محصول جدید بهش اضافه میشه، یکی از اساسیترین نیازها اینه که بتونیم تشخیص بدیم هر محصولی که غرفهدارها به پلتفرم اضافه میکنن چی هست و به چه دستهای تعلق داره. مثلا اگر یه محصولی «گلاب» بود باید تو دستهبندیِ محصولات پلتفرم، این محصول رو تو دسته «عرقیات» قرار بدیم و اگه «سینی چوبی» بود باید این محصول بره تو دسته «ظروف سرو و پذیرایی» و یا اگه اون محصول، «کتونی زنانه» بود باید اون رو تو دسته «کفش و دمپایی زنانه» طبقهبندی کنیم.
چرا دستهبندی محصولات برای باسلام مهمه؟
دستهبندی بهتر، بازدید بیشتر
جدای از اینکه دستهبندی درست محصولات باعث میشه کاربران از طریق قسمت «دستهبندی» راحتتر به محصولشون برسند، در واقع این کار برای ارتقاء و بهینه شدن SEO پلتفرم انجام میشه. به این صورت که هرچهقدر این دستهبندیها بهتر و دقیقتر و باکیفیتتر باشه، کاربرانی که توی گوگل سرچ میکنند بهتر بتونند محصولات باسلامی رو پیدا کنند. در واقع، درست بودن یا نبودن دستهبندی، به راحتی میتونه باعث افزایش یا کاهش میلیونها بازدید روزانه از طریق گوگل و موتورهای جستوجو بشه.
باسلام چیزی حدود ۸۰۰ نوع دستهبندی داره که هر محصول در یکی از این دستهها قرار میگیره. برای اینکه تشخیص بدیم یک محصول در کدام یک از این دستهبندیها قرار میگیره سال ۹۹ یک مدل Text Classification توسعه داده بودیم. البته اون اوایل، حدود ۶۰۰ دستهبندی داشتیم ولی طی این سالها تعدادش افزایش پیدا کرد. این توضیح هم اینجا لازمه که ما از این مدل، توی اپ «غرفهی من» هم استفاده کردیم. به این صورت که وقتی غرفهدار عنوان محصولش رو مینویسه ما اون عنوان رو به مدل میدیم و مدل سه دستهبندی رو به غرفهدار پیشنهاد میده و از بین اونها غرفهدار یکی رو انتخاب میکنه. به این صورت غرفهدار لازم نیست در تمام دستهبندیها بگرده و دسته مدنظرش رو برای محصولش انتخاب کنه.
این دستهبندیها مدام تغییر میکنند
در این مدت با یک چالش خیلی جدی روبرو شدیم که عملا توسعه رو بسیار هزینهزا میکرد و در نتیجه بهبودهای روی SEO با کندی مواجه بود. چالش جدی ما، تغییرات دائمی دستهبندیها بود. گاهی بنابه تشخیص تیم SEO لازم بود دو دسته باهم ادغام بشن و یا یک دستهبندی حذف یا اضافه بشه و یا از همه بدتر یک دستهبندی به چند دستهبندی ریزتر تقسیم بشه. در چنین شرایطی ما باید دوباره به اشکال مختلف و با فرایندهای غیربهینه و دستی، dataset رو تغییر و از اول مدل جدیدی توسعه میدادیم. علاوه بر توسعه مدل، از اونجا که دستهبندیهای سایت، به بسیاری از سرویسهای باسلامی متصل بود، تغییرات Back-end هم بسیار با درد و خونریزی زیادی انجام میشد.
بخاطر این چالشها، تیم SEO تمام تغییرات رو جمع میکرد و به صورت دورهای (مثلا سالی یک بار) به یک باره این تغییرات اعمال میشد و خود این فرایند مشکلات زیادی رو به دنبال داشت. با این وجود، مشکلات این ماجرا برای همه پذیرفته شده بود و در این چند سال اخیر دو سه باری درگیر تغییرات عمدهی دستهبندیها شدیم و همه فرآیندها و اقدامات غیربهینهاش رو به جون خریدیم. این ماجرا هر بار حداقل دو سه ماه از تیمها زمان میبرد.
مدلهای قبلی منقضی شدند
علاوه بر این چالش مهم، دقت نسبتا پایین مدل ما هم، کیفیت دستهبندیها و به تبع اون، SEO پلتفرم رو تحتالشعاع قرار داده بود. در روزهای اول باسلام قبل از اینکه اون مدل Text Classification قبلی توسعه داده بشه، خود غرفهدار مجبور بود بین تمام دستهبندیهای سایت بگرده و دسته مناسب برای محصولش رو انتخاب کنه. ما از همین دیتا برای آموزش مدل استفاده کردیم. به این صورت که دیتای ورودی ما عنوان محصولات بود و لیبل ما دستهبندیهای انتخابی غرفهداران بود. اینکه خود غرفهدار دستهبندی محصولات رو انتخاب میکرد علاوهبر تجربهکاربری بدی که برای غرفهدار بابت گشتن بین این همه دستهبندی ایجاد میکرد، باعث شده بود بخاطر خطای انسانی و کار سخت پیدا کردن دستهبندی مناسب، دقت اختصاص محصولات به دستهها خیلی بالا نباشه و از همین رو دیتاسِت ما کیفیت لازم رو نداشته باشه. ضمن اینکه تعداد دستهها هم بسیار بالا بود و تسک تبدیل به یک تسک نسبتا پیچیدهای شده بود. نبود استاندارد ثابت برای نوشتن عنوان محصول و باز بودن دست غرفهدار، پیچیدگی تسک رو بالاتر هم برده بود!
حالا نوبت AI است!
باوجود همهی این مشکلات، بازدید باسلام در سال گذشته بواسطه بهبودهای SEO ده برابر شد و از اون زمان تمرکز تیم باسلام رفت روی توسعه هرچه بیشتر SEO. در این راستا، اولین درخواست تیم SEO از ما این بود که سیستمی توسعه بدیم که ماهیت محصولات و ویژگیهای اونها رو از روی عنوان و توضیحات و یا حتی تصویر محصولات بدست بیاریم تا اونها بتونن از این طریق دستهبندیهای باکیفیتتر و ریزتر و دقیقتری ایجاد کنند. به نحوی قرار بود سیستم قبلی با تمام مشکلاتش کنار گذاشته بشه و با یک سیستم جدید که «ماهیت» و «ویژگیهای محصولات» رو تشخیص میده دستهبندی های دقیقتری بصورت پویا توسعه داده بشه.
بطور مثال اگر عنوان محصولی «پیراهن آستین بلند مردانه» بود، ما باید سیستمی داشته باشیم که اولا ماهیت این محصول رو «پیراهن» تشخیص بده، دوما ویژگیهایی مثل نوع «آستین» و «جنسیت» رو هم کشف کنه. خلاصه با این مساله مواجهیم که باید برای یک محصول «ماهیت» و «ویژگیها»ش رو تعیین کنیم. منظور از ماهیت، یعنی ماهیتا اون محصول چی هست. عسله یا مانتو. کت شلواره یا کیف چرمی. ویژگیهای محصول هم مشخصا میشه رنگ و وزن و جنس و چیزای شبیه به این.
آخرین تلاشها برای زیربار مسئولیت نرفتن
از نظر تیم SEO این درخواست منطقی بود، ولی برای ما بسیار پروژه سخت و چالشبرانگیزی بنظر میاومد. در پروژه Text Classification قبلی، ما با ۸۰۰ کلاس روبرو بودیم و با این حال دقت و کیفیت خوبی نگرفتیم. حالا با این وجود باید چیزی حدود صدها هزار ماهیت محصول و میلیونها ویژگی محصول رو تشخیص بدیم! عمدتا چالش اصلی ما تشخیص ویژگیهاست که بشدت بازه و دارای تنوع و گستردگی عجیبیه.
باید اعتراف کنم که ما مدتی از ساختن چنین سیستمی طفره رفتیم و هی عقب انداختیم؛ چون تقریبا غیر ممکن به نظر میرسید. ولی نهایتا کاری بود که باید انجام میشد و و ما در کمال ناامیدی، کار رو شروع کردیم :)
حل مساله
مسأله رو چطور شکستیم و چارچوببندی کردیم؟
تقریبا اواسط سال ۱۴۰۲ بود که عزممون رو جزم کردیم تا یک بار برای همیشه یک سیستمی ایجاد کنیم که تمام این مسائل رو حل میکنه و این نیاز زیرساختی یعنی تشخیص ماهیت و ویژگیهای محصولات رو برای تیم SEO برطرف کنه. ما مساله رو این طوری به چند زیرمساله شکستیم:
- سیستمی که یک لیستی از ماهیتهای معتبر رو ایجاد کنه. بهگونهای که با باتوجه به پویایی بازار قابلیت آپدیت داشته باشه.
- سیستمی که هر محصول رو به یک یا چند ماهیت نگاشت کنه. (سیستم Assign)
- سیستمی که ویژگیهای محصول رو تشخیص بده.
از اونجا که پیچیدگی مساله سوم بسیار بالا بود، کمتر تمرکز روی این مساله کردیم و بیشتر تمرکز ما روی ساخت دو زیرسیستم اول و دوم بود.
راهکارهای پیشین برای تشخیص و نگاشت ماهیت محصولها
مساله ماهیت (یعنی مساله اول و دوم) قبلا هم به دلایل مختلفی در باسلام مطرح بود و سیستمهای متعددی برای حل این مساله ساخته شد. اگر بخوام کمی به گذشته برگردم، اولین سیستمی که تو باسلام سعی داشت تا حدی این مساله رو حل کنه پروژه Tag بود. منطق پروژه Tag این بود که خیلی از کوئریهای کاربر، همون ماهیتهای محصول هستند. با یک سری پیشپردازش روی این کوئریها یک لیست اولیه از ماهیتهای محصول به دست اومد. و بعد، از روی رفتار کاربر و اینکه کاربر با چه کوئری، روی چه محصولی کلیک میکنه یک دیتاست شامل «عنوان محصول» و «ماهیت محصول» ایجاد شد. از اینجا به بعد مساله در چارچوب Classification حل شد. مدلی توسعه دادیم که از روی عناوین محصول، ماهیت محصول رو باید پیشبینی میکرد.
البته این راهکار دو عیب بزرگ داشت. اولا لیست ماهیتها محدود بود به یک لیست از قبل تعیین شده. و این برای بازار زندهای مثل باسلام که هر لحظه ماهیتهای جدیدی وارد میشه یک ضعف جدی بود. دوما تعداد لیست ماهیتها بشدت زیاد بود. و این یعنی مدل Classifier ما باید برای هر محصول، از بین حدودا سیهزار کلاس (ماهیت) یکی رو انتخاب کنه. که این تعداد کلاس بسیار زیاده و عملا تسک Classification با این حجم پیچیدگی دقت خیلی بالایی نداره. ضمن اینکه خود دیتاست ما هم خیلی تمیز نبود و بطور تقریبی و نه به شکل تمیز و نظارتشده این دیتاست ایجاد شده بود.
تلاشهایی هم در راستای بهبود دیتاست انجام دادیم. مثلا مدت زیادی رو برای تولید دیتاست بصورت دستی گذاشتیم. اما به دلیل مقیاس ناپذیری و کندی روشهای انسانی و دستی برای تولید دیتاست این روش خیلی خوب پیش نرفت. ضمن اینکه تقریبا تمام مشکلات قبل رو همچنان به همراه خودش داشت.
آزمایش روشهای گوناگون برای تشخیص ماهیت محصولات
به محض شروع این پروژه، از روشها و ابزارهای مختلفی برای به ثمر نشوندن کار استفاده کردیم. مثلا یکی از ابزارهای ما یک مدل Embedding بود که خود ما تو باسلام توسعهاش داده بودیم و دقت خوبی روی عنوان محصولات باسلامی داشت. N-gram (یک الی چهار) عنوان محصولاتمون رو به این مدل دادیم و Embedding شون رو ذخیره کردیم. از طریق این وکتورها یک مدل کلاسترینگ سلسلهمراتبی توسعه دادیم تا بتونیم بعدا به روشی برای هر کلاستر یک نماینده تعیین کنیم که این نمایندهها در واقع بشه ماهیتهای ما. روی این روش خیلی وقت گذاشتیم و نتایجش نسبتا بد نبود. اما باوجود داشتن یک مدل کلاسترینگ قوی، خیلی این روش برای ادامه کار قابل اتکا نبود. چرا که این روش در تشخیص نماینده هر کلاستر که همان ماهیتهای ماست ضعف جدی داشت.
یکی دیگه از ابزارهای که استفاده کردیم، APIهای شرکت Open-AI بود که در ادامه برای بهبود روش قبلی ازش استفاده شد. به این شکل که اول وکتور تمام نمایندههای بدست آمده در مرحله قبل -که همون ماهیتهای انتخابی ما هستند- توسط مدل Embedding خودمون، در یک Vector DB ذخیره میشد. و بعد برای حل مساله دوم یعنی نگاشت دادن محصولات به یک ماهیت، Embed هر محصول باسلامی تولید میشد و از طریق Vector DB و با شباهت کسینوسی، یک لیست محدودی از مشابهترین ماهیتها به آن محصول دریافت میشد. این مرحله به شکلی در نقش فیلتر کردن یک لیست کاندیدایی از مرتبطترین ماهیتها عمل میکرد. در آخر هم به کمک API مدل GPT-4 از بین ماهیتهای کاندید، ماهیت محصول نهایی انتخاب میشد. به این شکل که به مدل عنوان محصول و ماهیتهای کاندید رو میدادیم و از طریق Function Calling از مدل میخواستیم براساس عنوان محصول داده شده ماهیت نهایی رو از بین گزینههای موجود انتخاب کنه. این کار هم دو اشکال جدی داشت. یکی اینکه همونطور در بالاتر عرض کردم خیلی روی دقت مرحله قبل نمیشد حساب کرد. دوم اینکه این روش اخیر خیلی مقیاس پذیر نبود چراکه استفاده از API مدل GPT-4 روی پروداکشن هزینه زیادی برای ما داشت.
از روشهای Ngram-based و پردازش lexical زبان طبیعی هم استفاده کردیم. حتی در ترکیب با روشهای AI-based. اما با این حال خیلی موفقیت آمیز نبود. تقریبا هر ایده و روشی که به ذهن ما میاومد روی یک مقیاس کوچکی از محصولات آزمایش میکردیم. چه برای ایجاد یک لیست ماهیت معتبر و چه برای نگاشت محصولات به ماهیت. همگی بینتیجه موندند. ضمن اینکه با وجود چنین تلاشهایی، نهایتا ما تمرکزمون روی مساله اول و دوم -یعنی ایجاد مکانیزم پویا برای لیست ماهیت ها و نگاشت اونها به محصولات- بود؛ در حالیکه مساله تشخیص ویژگیهای محصول همچنان روی زمین مونده بود و هیچ تلاشی در راستای حل اون نکرده بودیم.
یکی از تیرهای آخر: LLM
در کنار تمام این مسیرها، استفاده از LLM ها هم توی ذهن ما بود. طبق مقاله LIMA فهمیدیم اگر یک LLM نسبتا کوچیک یا متوسط (مثلا ۷b یا ۴۰b) رو با تعداد داده بسیار کم ولی بسیار باکیفیت فاینتیون کنیم، دقتش در اون تسک از GPT-4 هم بیشتر میشه. بعبارتی این مقاله قدرت LLMهای کوچیک و راهکار فاینتیون رو نشون میداد. منتها با این حال خیلی امیدی به این مسیر نداشتیم و برای همین، LLM تقریبا آخرین تیر ما برای حل این مساله بود. دلیل اینکه نمیتونستیم به مسیر LLM ها اعتماد کنیم این چند مورد بود:
- اولا دامنه تسکی که ما از LLM میخوایم با دامنهای که LLM های اوپن سورس آموزش دیدند سازگار (Adopt) نبود. تسک ما به زبان فارسی است و برای چنین تسکی هوشمندی در حد GPT3.5 یا GPT4 لازمه که در بین مدلهای اوپن سورس یافت نمیشد.
- دوما مسیر نوظهوری بود و با چالشهاش آشنا نبودیم و خب باتوجه به نزدیک بودن پایان کار (Deadline) اینکه روی این مسیر کاملا مبهم وقت بگذاریم ریسک بالایی داشت.
- سوما بعید میدونستیم حتی اگر این مسیر روی کاغذ جواب بده، بشه با سختافزارها و امکانات محدود ما عملیاتیاش کرد.
با این حال، این مسیر رو هم با اکراه و بدون هیچ امیدی آزمایش کردیم. ابتدا سعی کردیم محیط آزمایش رو انقدر کوچیک کنیم که سرعت انجام آزمایش بره بالا و اگر قرار بود این مسیر شکست بخوره سریعتر تکلیفش مشخص بشه. بخش کوچکی از یکی از دیتاستهای قدیمیمون (که کیفیت بالایی نداشتند و کلا گذاشته بودیم شون کنار) رو برای آزمایش LLM برداشتیم. یه چیزی حدود ۶۵ تا ماهیت محصول رو انتخاب کردیم (مثل پیراهن، عسل، مبل ۷نفره و..) و به ازای هر ماهیت حدود ۴۵ محصول برداشتیم و خلاصه یک دیتاست با ۳۰۰۰ نمونه داده (Sample) ایجاد کردیم. از اونجا که مکانیزم RLHF آشنا بودیم و تو این مسیر مطالعاتی داشتیم با کتابخانه TRL سعی کردیم ذیل تسک SFT، یک LLM رو فاین تیون کنیم. با متدهایی مثل Lora و Qlora هم آشنا بودیم بنابراین این کار راحت و سریع و بدون دردسر روی یک GPU 3090 انجام شد.
بعد از انجام فاینتیون، نتیجه بسیار امیدبخش بود و اصلا انتظار نداشتیم. LLMی که در حالت فاینتیون نشده، یک جمله فارسی معنادار نمیتونست تولید (Generate) کنه مثل بلبل برای ما ماهیت محصول رو تولید میکرد اون هم با دقت (accuracy) حدودا ۷۵٪ روی دیتاست تست. این رو هم اضافه کنم که از LLM خواستیم پاسخ رو در قالب یک Json ارائه بده تا بشه پاسخ رو Parse ش کرد. تولید json رو هم با دقت خوبی انجام داد و تقریبا همه تولیدات LLM از ساختار json که ما میخواستیم تبعیت میکرد.
همچنان تردید درباره LLM
با اینکه نتایج قابل قبول بود و این مسیر تیره و تاریک، کمی روشن و امیدبخش شد، اما با این حال نیمه خالی لیوان میگفت این تسک آزمایشی، تسک سادهایه و از هر مدل Classification هم برمیاد (البته اگر بخوایم خوشانصاف باشیم با ۳هزار نمونه داده هیچ مدل Classification نمیتونه با این دقت روی ۶۵ کلاس تسک رو انجام بده). ضمن اینکه تسک اصلی ما که تشخیص ماهیت و ویژگیهای محصوله که بسیار تسک پیچیدهتری است. بنابراین تسک رو پیچیدهتر کردیم تا کمی به تسک اصلی نزدیکتر باشه. با همون تعداد سمپل این بار تعداد ماهیتها رو افزایش دادیم. یعنی با ۳۰۰۰ نمونه داده، ولی با ۴۷۵ ماهیت محصول. بعبارتی بطور میانگین به ازای هر ماهیت، ۶ محصول در دیتاست موجوده. این بار با این دیتاست، مدل رو فاینتیون کردیم. نتایج در ابتدا ضعیف بودند، ولی با کمی تیون کردن هایپرپارامترها به عدد ۷۳٪ رسیدیم.
اینجا اطمینان ما از مسیر خیلی بیشتر شد. با این حال تسک رو باز ده برابر پیچیدهتر کردیم. این بار تسک رو خیلی بیشتر از قبل شبیه به تسک اصلی کردیم. در دو آزمایش قبلی دیتاست ما به این شکل بود که به ازای هر محصول یک «ماهیت محصول» نگاشت شده بود و قرار بود فقط یک ماهیت محصول پیشبینی کنه. اما این بار از دیتاستی استفاده کردم که به ازای هر محصول، چندین ماهیت محصول نگاشت میشه. مثلا برای محصولی مثل “مانتو کتی مخملی رنگ کبریتی” لیستی از ماهیتهای [‘مانتو’,‘مانتو کتی’,‘مانتو کتی کبریتی’] نگاشت میشد. هدف ما از این کار این بود که خروجی مدل یک json با پیچیدگی متوسط باشه. به این صورت :
{“entity_of_1″:”مانتو”,
“entity_of_2″:”مانتو کتی”,
“entity_of_3″:”مانتو کتی کبریتی”}این بار از یک دیتاست با حجم ۹۳هزار نمونه داده استفاده کردیم که در اون از ۲۰۰۰ ماهیت استفاده شده بود. بعبارتی به ازای هر ماهیت بطور میانگین ۵ محصول در دیتاست بود. با این تسک، LLM رو دوباره فاین تیون کردیم. این بار LLM در انجام تسک شکست خورد. تغییرات زیادی رو هایپرپارامترها دادیم ولی وضعیت عوض نشد. احتمال دادیم اگر با LLM های دیگه تست کنیم شاید بهتر باشه. تا الان تمام آزمایشات ما با مدل Zephyr-7b انجام میشد. از اینجا به بعد رفتیم سراغ LLma2-7b. روی لاما با موفقیت تسک انجام شد. اون هم با دقت ۸۵٪ !
ساخت مدل نهایی با LLM
از اینجا به بعد دیگه دلمون قرص شد. تقریبا صددرصد مطمئن شدیم که میتونه تسک ماهیت و ویژگیهای محصول رو انجام بده. یک نکته اینجا باقی موند و اون اینکه اگه سراغ LLM بریم از اونجا که بهازای هر محصول بصورت Generative ماهیت و ویژگیها تولید میشه عملا اون چارچوببندی مساله که از قبل تعریف کردیم بیخاصیت میشه. که برامون مهم نبود و گذاشتیمش کنار. الان فقط یک چیز نیاز بود. و اون هم چیزی نبود جز دیتاست. به کمک API های شرکت Open-AI (در نسخه اول با GPT3.5) دیتاستی درست کردیم که به ازای هر محصول یک json داشت متشکل از ماهیت و ویژگیهای اون محصول. با یک حساب کتاب سرانگشتی فهمیدیم باید این دیتاست حداقل ۳۰۰ هزار نمونه داده داشته باشه تا LLM ما خوب تسک رو یاد بگیره. از اونجا که تولید این دیتاست هزینه نسبتا زیادی داشت، با آزمایشات قبلی از مسیر تولید دیتاست با ChatGPT هم مطمئن شده بودیم و با خیال راحتی این هزینه رو پرداختیم. تقریبا یکی دو هفته هم روی پرامپت کار کردیم و در نهایت در مرحله اول با دیتاستی که از طریق API مدل GPT3.5 بوجود اومده بود مدل LLma2-7b رو فاینتیون کردیم و با موفقیت این مدل تسک موردنظر رو یاد گرفت.
برای مثال اگر فرض کنیم عنوان و توضیحات محصولی که غرفهدار نوشته به این شکل باشه:
title = “““: ست شابلون ژله ای دو قلو صریر 20سانتی 1 عدد
یک عدد ست شابلون ژله ای دو قلو سریر 20سانتی متر
با کیفیت مناسب و صادراتی
شامل دو تکه شابلون ژله ای
در چهار رنگ سبز، قرمز، نارنجی و آبی موجود است.
پخش لوازم التحریر کیان”””خروجی تولید شده توسط LLM به این شکل بود:
{
“attributes”: {
“تعداد تکه“: ”2”,
“طول“: ”20 سانتیمتر”,
“رنگها“: ”سبز، قرمز، نارنجی، آبی”,
“کیفیت“: ”مناسب و صادراتی”},
“product_entity”: “ست شابلون ژله ای”
}ارزیابی اولین LLM باسلام
در تستهای اولیه نتایج خوبی دیدیم. تقریبا در ۹۸ درصد مواقع ساختار json رو رعایت میکرد و این خیلی اتفاق خوبی بود. اما با این حال لازم بود که ارزیابی عددی دقیقی هم داشته باشیم. روشهای ارزیابی LLM ها یا براساس روشهای آماری روی کلمات و کاراکترها هستند، یا مبتنی بر LLM و یا براساس Embedding. پس از بررسی این روشها فهمیدیم بیشتر به درد تسکهایی میخورند که LLM به زبان انسانی و بصورت روان متن تولید میکنند و برای تسکی که یک ساختار json داره خیلی به کار نمیاد. تنها روشی که به ذهن مون اومد این بود که با کمک تیم سئو روی تعداد محدودی محصول، لیبل بزنیم و بصورت سنتی عدد Recall و Precision و F1-score مدل رو برای این تسک حساب کنیم. هرچند بدلیل سختی ارزیابی دیتاست ارزیابی ما خیلی بزرگ نبود ولی بطور شهودی میتونست عدد نزدیک به واقعیت بده. حدودا با این روش به عدد ۷۰ الی ۷۵ درصد رسیدیم.
چالش هنوز به پایان نرسیده. مسأله Inference را چه کنیم؟
تا اینجای کار ما یک LLM فاین تیون شده داریم که میتونه تسک ما رو انجام بده. ولی خب این حرف معنیاش این نیست که کار ما تموم شده و پروژه به پایان رسیده. حالا ما چیزی حدود ۱۳ میلیون محصول داریم که باید برای تک تک این محصولات ماهیت و ویژگیهاش توسط مدل تولید (Generate) بشه. کتابخانه Transformer هاگینگفیس تاخیر (Latency) بسیار بالایی داره و عملا با این کتابخونه تولید این حجم محصول نشدنیه. برای اینکه عمق فاجعه رو متوجه بشیم این رو باید بگیم که ما حساب کردیم اگر همین الان شروع میکردیم به تولید ماهیت و ویژگیهای این ۱۲ میلیون محصول، حدودا یک سال دیگه این کار به پایان میرسید. پس تا چالش Inference رو حل نکردیم، نمیشه از پایان پروژه صحبت کرد.
یکی از کارهای جدی ما این بود که Inference Engine های موجود که برای LLM ها توسعه داده شدند رو ارزیابی کنیم و به استک باسلام اضافه کنیم. بلاگهایی مثل این خیلی به سرعت بررسیهای ما کمک کرد و باعث شد اولین و آخرین Engine که تست میکنیم Vllm باشه. با این Engine میشد ماهیت و ویژگیهای هر محصول رو در ۳۳ صدم ثانیه روی GPU 3090 تولید کرد و خب این عدد خیلی خوبی بود. تقریبا تمام GPU هامون رو برای Inference فعال کردیم، یکی دوتا هم کرایه کردیم و در عرض تقریبا یک ماه کل محصولات ماهیت و ویژگیهاشون در قالب json ذخیره شد.
بهبود با مدل GPT4
در قسمت گفتیم در مرحله اول برای ساخت دیتاست از GPT3.5 استفاده کردیم. این مدل با وجود هزینه کم و بهصرفگی خیلی بالایی که داشت دیتاست خیلی باکیفیتی درست نکرد. در نتیجه با اینکه در ارزیابیهای اولیه به عددهای خوبی رسیدیم، اما در مقیاس ۱۴ میلیون محصول، ضعفهای خودش رو نشون داد و دیدیم خیلی خروجی برامون کاربردی نیست. تو این مرحله تصمیم گرفتیم بریم سراغ ورژن دوم دیتاست و این بار با کمک GPT4 دیتاست رو ساختیم. این رو هم اضافه کنم که تو این مدت روی پرامپت و هایپرپارامترها هم کمی بهینهسازی انجام دادیم و تونستیم برخلاف دفعه قبل که با ۳۰۰هزار نمونهداده آموزش دادیم این بار با فقط ۵۰ هزار نمونهداده مدل LLama-2 رو آموزش بدیم. این بار تغییراتی هم در ساختار Json خروجی دادیم و در کل بخاطر دیتاست ساخته شده توسط GPT4 و این تغییرات جزئی بهبود خیلی خوبی روی خروجی بوجود اومد.
برای مثال اگر محصول ما همان محصول قبلی باشه که بالاتر ذکر شد، خروجی توسط نسخه دوم به این شکل شد:
{
“attributes”:{
“تعداد در بسته”:[“1 عدد”],
“نوع”:[“ژله ای”],
“تعداد قلو”:[“دو قلو”],
“اندازه”:[“20 سانتی متر”],
“کیفیت”:[“مناسب“,”صادراتی”],
“تعداد تکه”:[“دو تکه”],
“رنگ”:[“سبز“,”قرمز“,”نارنجی“,”آبی”],
“برند”:[“پخش لوازم التحریر کیان”]
},
“product_entity”:[“لوازم التحریر“,”لوازم هنری“,”شابلون“,”ست شابلون ژله ای”]
}ایجاد ساختار Knowledge graph
این رو هم بگم که یکی از ابتکارات مهمی که در این پروژه به کار گرفته شد این بود که برای ذخیرهسازی دیتا از معماری گراف استفاده کردیم و بعبارتی یک Knowledge Graph ساختیم که دو مزیت خیلی مهم بهمون داد.
اولین مزیت این بود که امکان استنتاج کردن از روی دیتا برامون بوجود اومد. مثلا محصولی فرض بگیرید که ماهیتش “مانتو کتی” است و در بین ویژگیهای اون محصول “رنگ:سیاه” هم وجود داره. حالا شما میخواهید تمام “مانتو مشکی” های پلتفرم رو توی یک لیست بیارید. از اونجا که قبلا در گراف ما، رابطه مانتو→ مانتو کتی برقرار بوده (به این معنی که مانتو کتی یک نوع مانتو است) و همچنین چون رابطه سیاه=مشکی نیز وجود داره، در نتیجه این محصول فرضی ما ذیل دستهبندیِ “مانتو مشکی” هم قرار میگیره.
دومین مزیت این ساختار اینه که بسیار منعطف هست. چون ما سیستم استنتاج از روی دیتا داریم، هرکس هر فکتی درمورد هرچیزی وارد کنه، براساس گراف ساخته شده، استنتاج میشه (شبیه مثال بالا). اگر هم متوجه شدیم فکتی که وارد شده اشتباه بوده به راحتی بدون اینکه جاهای دیگه رو خراب کنه از دیتا حذف میشه و استنتاج اصلاح میشه. درمورد ساختار گراف و ساخت موفق و حرفهای Knowledge graph یک بلاگ مفصل باید نوشته بشه که انشالله همکاران ما زحمتش رو خواهند کشید.
در آینده به کجا خواهیم رفت؟
این پروژه نهایتا به ثمر رسید و مشکلی که باید، حل شده. ولی داستان در واقع به پایان نرسیده و تازه شروع شده.
ساخت چرخه و پیادهسازی مکانیزم Alignment
یکی از جدیترین چالشهای ما توهم (و یا همون hallucination) خود LLM بود که در این پروژه باعث میشد LLM ماهیت و ویژگیهای محصول رو به غلط تشخیص بده و باعث کاهش دقت کلی سیستم بشه. تلاشهای زیادی کردیم تا این مساله رو با روشهای صرفا مهندسی حل کنیم. از کار کردن با استراتژیهای تولید متن توسط LLM ها گرفته تا روشهای سنتیتر و حتی کمک گرفتن از دیتای یک LLM قویتر مثل GPT-4.
به این نتیجه رسیدیم این مساله عمیقا به کانتکس پلتفرم وابسته است و LLM چنین اطلاعات زمینهای از پلتفرم نداره و به زمین پلتفرم خیلی آگاه نیست. اینجا بود که به فکر استفاده از کامیونیتی برای جمعآوری دیتا افتادیم تا بتونیم با ایجاد یک چرخهی بازخورد (Feedback loop) در طول زمان بازخوردها رو مدل بدیم و مدل رو بصورت ادامهدار (Continuous) فاینتیون کنیم. ایده ما این بود که اگر مسیر (Journey) اضافه شدن محصول به باسلام رو بطوری بازطراحی (Redesign) کنیم که بشه از همان نقطه ورود محصول، دیتای تمیز از غرفهداران دریافت کنیم، خیلی سریع میتونیم LLM رو با این دیتا بهبود بدیم. البته این نکته رو هم بگم که قرار نیست دست غرفهدار رو در نوشتن ببندیم و طبق سیاست باسلام غرفهدار همچنان آزادی عمل خواهد داشت.
اینجا لازم بود دو کار انجام بشه. یکی بازطراحی پلتفرم تا بتونیم از غرفهدار دیتای تمیز دریافت کنیم. کار دوم این بود که یک سیستم بازآموزی (Retrain) برای مدل توسعه بدیم تا از دیتای تمیز استفاده کنه و خودش رو اصلاح کنه. به شکلی که بازخوردهای کوچک غرفهداران روی کل خروجی مدل تاثیر بگذاره. اینجا بود که رفتیم سراغ مرحله دوم مکانیزم RLHF. حتما میدونید که در این مکانیزم بعد از انجام مرحله SFT، با کمک یادگیری تقویتی (Reinforcement Learning) از بازخوردهای انسانی برای بهبود خروجی مدل و انطباق بیشتر با ترجیحات انسانی استفاده میکنند. بعد از کمی مطالعه در این زمینه دیدیم که دستاوردهای خیلی خوبی در این زمینه بوجود اومده که باعث میشه از این مکانیزم به شکل کارآمدتری استفاده کرد. روشهای بهبودیافتهای مثل DPO, IPO و KTO که دیگه حتی لازم نیست از RL هم استفاده بشه.
این سیستم در حال پیادهسازی در باسلامه و از اونجا که هم سمت پلتفرم تغییرات لازمه و هم سمت AI باید توسعههایی داده بشه، اجراش کمی زمان خواهد برد.
ورود به دنیای تصویر برای غنیتر کردن دیتا
یکی از کارهای دیگهای که در راستای بهبود این پروژه میخواهیم انجام بدیم اینه که دیتای تصویر رو هم اضافه کنیم. یعنی همونطور که به کمک عنوان و توضیحات محصول، برای اون محصول یک کاتالوگ شامل ماهیت و ویژگیهای اون محصول ساخته میشه، از تصویر محصول هم برای غنیتر کردن این دیتا کمک بگیریم. برای این کار لازمه وارد حوزه Vision-language models یا همون VLM ها بشیم که یکی از مهمترین کارهای ما در سال پیشِرو است.
ساخت مدل از روی Knowledge Graph
یکی از کارهای موثری که میشه انجام داد اینه که از دیتای گراف دانش محصولات باسلامی، برای ساخت مدلهای هوشمصنوعی مختلف، بخصوص مدلهای Graph-based استفاده کنیم. در حال حاضر یکی از نیازهای ما ساخت مدلهای Embedding تا بتونیم در جای جای پلتفرم استفاده کنیم.
باسلام و شما!
ممنون که این مطلب نسبتا طولانی رو خوندید. و خب، اگه تا اینجای متن رو اومدین، از نظر ما آدم جالبی هستید. برای همین میخوام ازتون دعوت کنم که با هم آشنا بشیم. اگه شما هم به این جور مسالههایی علاقهمند هستید و براتون مهمه که با حل این مسائل، کسبوکارهای آنلاین رونق بیشتری پیدا کنه، خوشحال میشیم با شما آشنا بشیم. اگه دوست داشتید، از طریق این ایمیل به ما خبر بدین: px@basalam.com
ضمنا کانال تلگرامی بنده رو هم میتونید از اینجا ببینید.
تشکرات
طبیعتا این حجم کار، کار یکی دونفر نیست و تیم پرکار و پرتلاشی پشتش هست. در پایان پست خواستم تشکر کنم از تمام دوستانی که در این محصول نقش مهمی ایفا کردند.
تیم SEO
یک تشکر ویژه از آقا پیمان خلیلی مدیر سئو باسلام و همچنین دیگر دوستان تیم سئو متین رستممنش و علی(فرعلی) جلیلی که اگر نبود فیدبکهای این دوستان، بهبودها برای نسخه دوم حاصل نمیشد.
تیم MatchMaking
از علی اصغر رجبی بابت زحماتی که برای ادامه کار کشید و نسخه دوم رو توسعه داد. از مجید سعدی بخاطر Post-processing و توسعه مسیر فیدبک لوپ و Alignment.
از جواد هلالی و صادق سرداری و عرفان صابری بابت زحماتی که در Back-end، و از سید علی صحفی بابت زحماتی که در Front-end کشیدند و به این شکل تونستیم سرویس رو رنگ و رو بدیم تا بشه روش توسعههای بعدی رو داد.
از علیرضا ربانی بخاطر زحماتی که در UI/UX سرویس و همچنین طراحی پوستر اعلام انتشار مدلها کشید.
یک تشکر ویژه از حامد آقاجانی که متن وبلاگ رو بازنویسی کرد و اون رو از لولو به هلو تبدیل کرد.
و در آخر تشکر از علیرضا آراسته، حسام سرکشیکیان و کوروش سلیمانی که به خوبی این مسیر رو رهبری فنی و پروداکتی کردند.
فراتر از باسلام
یک تشکر هم از آقای خلیلی شجاع حتما باید داشته باشم بخاطر نقش الهامبخش ایشون در جلسات مشاوره.
همچنین بچههای هاگینگ فیس که در پیشبرد دانش AI خیلی نقش دارند.
از سمآلتمن تشکر نمیکنم چون پولش رو گرفته :)
تمام.
مطلبی دیگر از این انتشارات
پیادهسازی جستوجوی تصویری در باسلام: یک تجربه مقیاسپذیر
مطلبی دیگر از این انتشارات
روانشناسی تست نرمافزار: چرا فرآیند تست در سازمانها به درستی پیش نمیرود؟
مطلبی دیگر از این انتشارات
چالش روانخوانی فونت در باسلام