

چطور نرمافزار باسلام را برای تبلیغات تلویزیونی مقیاسپذیر کردیم؟

باسلام در سال ۱۴۰۱ وارد یک کمپین تبلیغاتی تلویزیونی بلند مدت شد. در این مقاله خواهید خواند که تیم مهندسی باسلام، پیش از آغاز این کمپین چطور زیرساخت و نرمافزار این پلتفرم را برای ترافیک تبلیغات تلویزیونی آماده کرد تا به مقیاس پذیری بالا برسد. در این مقاله دربارهی ۲ بخش این پازل شامل طراحی و اجرا که طی ۴۵ روز انجام شد، خواهید خواند. اگر مهندس نرمافزار یا مدیر مهندسی (Engineering manager) -چه در حوزه نرمافزار و چه غیر از آن- هستید، ممکن است خواندن این مقاله -که ۹ دقیقه زمان میبرد- برای شما جالب باشد.
۴۵ روز تا کمپین تلویزیونی
قرارداد اجرای کمپین، بعد از چندین ماه فراز و فرود در تصمیمگیری و توافق، ۱ آذر ۱۴۰۰ بسته شد و آژانس تبلیغاتی اعلام کرد فاصلهی کمی داریم تا روزی که باید روی آنتن باشیم. ما باید ظرف یک و نیم ماه زیرساخت و نرمافزار را آمادهی این کمپین میکردیم؛ یعنی باسلام هم بتواند زیر ترافیک بیشتر تاب بیاورد و پایدار (Stable) بماند، هم سرعت پاسخگویی نرمافزار (Response time) افت نکند بلکه بهبود یابد، و هم با توجه به افزایش توجهات، ضریب اطمینان از امنیت نرمافزار بالاتر برود.
میدانستیم که تلویزیون یعنی ترافیک بیشتر، ولی چقدر بیشتر؟ معلوم نبود؛ هیچ تخمین و اطلاعات نسبتا مفیدی قابل دسترسی نبود. نه مشاوران آژانس تبلیغاتی در این مورد میتوانستند عدد و رقمی بگویند و نه از تجربهی استارتاپهای مشابه -مثل ازکی که آن روزها روی آنتن بود- میتوانستیم به تخمین نسبتا دقیقی برای باسلام برسیم. از یک سو میشنیدیم که تبلیغات تلویزیونی traffic peak (ترافیک لحظهای زیاد) ایجاد میکند و از سویی میشنیدیم که این خبرها هم نخواهد بود. به هر حال بسته به جذابیت تیزرها، حجم و ساعت پخش، میزان ارتباط گرفتن کاربر با محتوا و پارامترهای دیگر، شرایط ما شرایط منحصر به فرد خودمان خواهد بود. در هر صورت تصمیم گرفتیم برای مقیاسی به مراتب بزرگتر خودمان را آماده کنیم. چه تبلیغات آن ترافیک را برای ما ایجاد میکرد چه نمیکرد، در هر صورت این هدف، نرمافزار باسلام را از جهات مختلف بهتر میکرد.
آمادگی برای ترافیک ۶۰ برابری
ابتدا به آمادگی برای ترافیک ۱۰۰ برابری فکر کردیم، اما برای جلوگیری از ایجاد اضطراب غیرضروری در تیم، به ۶۰ تقلیل دادیم. ضمن این که میتوانستیم بعد از رسیدن به مقیاس ۶۰ برابری، در صورت نیاز به ۱۰۰ برابر و بیشتر هم برسیم، با آرامش بیشتر. در آذر ۱۴۰۰ ۱۵۰۰ RPS داشتیم و باید برای ۹۰,۰۰۰ RPS آماده میشدیم. شدنی بود؟ برای کل نرمافزار باسلام، تقریبا نه، اما برای بخشی از آن، چرا.
استراتژی آمادگی برای مقیاس پذیری
تقریبا مثل هر نرمافزار مشابهی، دیتاسنتر، شبکه، load balancerها، سرورهای فیزیکی، زیرساخت Orchestration، وبسرورها، دیتابیسها، Message broker ها، کشها، اپلیکیشنها یا میکروسرویسها و سرویسهای شخص ثالث، اجزای اصلی نرمافزار باسلام هستند. برای مقیاسپذیری پایدار، یک استراتژی طراحی کردیم که پنج بخش داشت:
- تضمین حیات قابلیتهای حیاتی
- حذف نقاط حساس
- پردازش کمتر
- پردازش بهینهتر
- امنیت بیشتر
برای اینکه بتوانیم این ۵ کار را به نتیجه برسانیم، نیاز داشتیم خودبسنده باشیم تا تصمیمات سریع بگیریم و حتی یک ساعت را هم از دست ندهیم. خودبسندگی را به عنوان یکی از اصول در نظر گرفته بودیم.
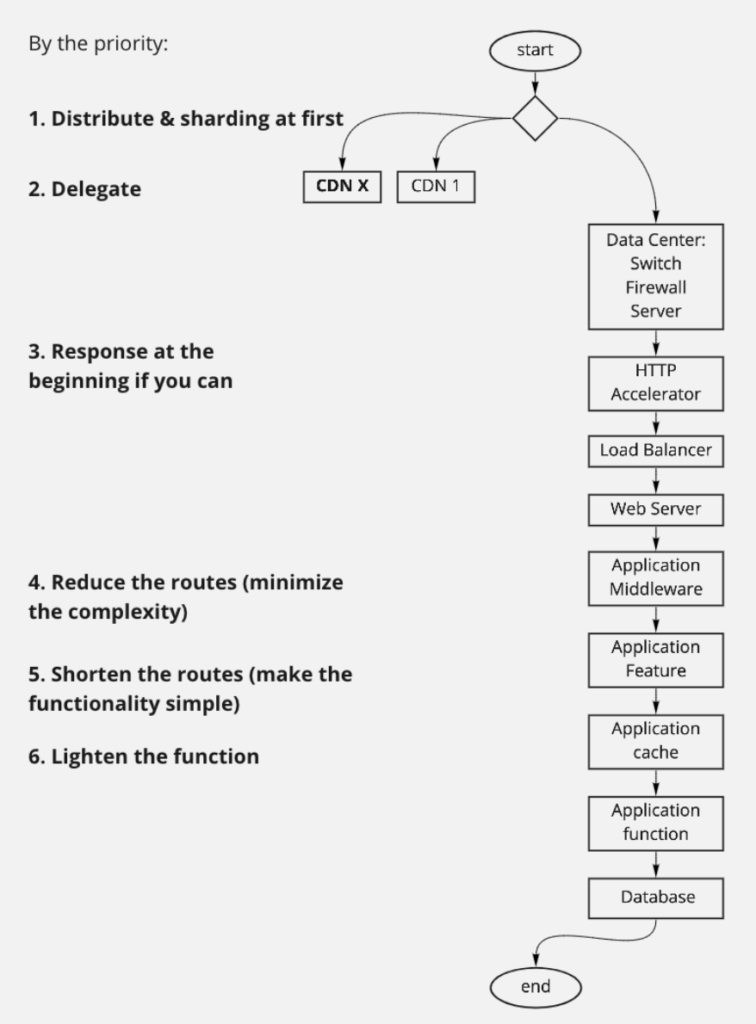
و اما شرح پنج بخش این استراتژی:
۱. تضمین حیات قابلیتهای حیاتی
خوب حل کردن صدها مساله در یک زمان کوتاه تقریبا نشدنی است، اما خوب حل کردن ده مساله در زمان کوتاه شدنی است. نیاز نبود کل باسلام را مقیاسپذیر کنیم. بنابرین به سرعت لیست Feature های حیاتی از دهها قابلیت باسلام را نوشتیم. احتمالا هم کسر کوچکی از نرمافزار، کسر بزرگی از ارزش باسلام را تشکیل میداد.
- صفحه اول
- سیستم احراز هویت
- موتور جستجو
- صفحه محصول
- کل فرآیند خرید
- چت
همزمان از بچههای محصول خواستیم که چنین لیستی را به ما بدهند، اما ما کار را طبق لیست خودمان شروع کرده بودیم و زمانی برای از دست دادن نداشتیم. چندین روز بعد که لیست مورد نظر محصول را دریافت کردیم، بسیار منطبق با تشخیص خودمان بود و ما به لطف خودبسندگی، زمانی را در انتظار از دست نداده بودیم. حسن لیست جدید این بود که تمام قابلیتهای باسلام را به ترتیب اولویت مشخص کرده بود و ما میتوانستیم در شرایط بار یا load بالا، به ترتیب از انتهای لیست قابلیتهای باسلام را خاموش کنیم.
برای این که بتوانیم کنترل روشن و خاموش کردن قابلیتها را در دست داشته باشیم، نیاز بود سرویس Feature flag را در سراسر محصول بگنجانیم و پایداری خود این سرویس را هم تضمین کنیم.
همهی این اولویتبندی و تصمیمگیری مصداقی است از Graceful degradation در مهندسی نرمافزار. وقتی نرمافزار زیر فشاری بیش از حد تحملاش قرار میگیرد، برازنده است که به طور کلی پایین نیاید و صرفا قابلیتهایش تقلیل یابد یا به بخشی از کاربران سرویس دهد. در یکی از جلساتی که با موضوع مقیاسپذیری (Scalability) با یکی از مهندسان ارشد گوگل داشتیم، شیوهی Graceful degradation مان را معرفی کردیم، ایشان علاوه بر تایید راهکار، اشاره کرد که در سرویسهای Ads گوگل، به طور خودکار و با استفاده از مدلهای هوش مصنوعی این کار -که آنجا به Degraded processing شناخته میشود- انجام میشود.
۲. حذف نقاط حساس
دو عامل رایج در Collapse کردن نرمافزارها، Bottleneck (گلوگاه)ها و SPoF (Single Point of Failures) ها هستند.
گاهی یک Query، یک کد غیر بهینه یا یک راهکار بد (مثلا پردازش غیرضروری) در ترافیک بالا تبدیل به گلوگاه میشود و کل سرعت نرمافزار را پایین میآورد؛ این حالت خوشبینانه است. در حالت بدبینانه آن گلوگاه تاب نمیآورد، Crash میکند و بسته به معماری نرمافزار حتی میتواند باعث Cascading failure شود و کل نرمافزار را پایین بیاورد. پس سعی کردیم تمام گلوگاهها را با تست فشار (Load test) ها شناسایی کنیم و به شیوههای مختلف آنها را رفع یا حذف کنیم.
در مورد SPoFها هم همین کار را باید میکردیم. در میکروسرویسهای باسلام و زیرساخت نرمافزاری هیچ SPoFای نداشتیم. زیرساخت باسلام را ۶۰ Device (سرور، سوییچ، Firewall -که بعدا اضافه شد- و غیره) تشکیل میدادند و SPoFای در آنها نبود، اما در سرویسهای شخص ثالث از جمله سرویس پیامک، اتکا به ۲ سرویسی که داشتیم ریسکی بود. تنها SPoFای که تقریبا نمیتوانستیم برایش کاری بکنیم خود دیتاسنتر بود. بسنده کردیم به جلساتی که با مدیران دیتاسنتر گذاشتیم و سطح اهمیت برنامهی پیش رو و انتظارات و SLA را همرسانی کردیم.
درگاههای پرداخت هم با این که متعدد بودند، اما در ساعات مختلف عملکردهای مختلفی در Conversation rate و Tech performance نشان میدادند. یکی از کارهایی که در برنامه گذاشتیم این بود که نرمافزار به صورت خودکار اینها را تشخیص بدهد و سوییچ کند.
۳. پردازش کمتر
معماریهای پر پیچ و خم نرمافزار معمولا در تیمهای جوان پیدا میشوند و ما هم از این وضعیت مستثنی نبودیم. معماریهایی که در ابتدا با هدف نظمبخشی به کد و تضمین حفظ سرعت توسعه نرمافزار ایجاد میشوند، اما به مرور زمان نه تنها این خاصیت را از دست میدهند بلکه دقیقا عکس آن هدف عمل میکنند. علاوه بر آن، این معماریهای پر پیچ و خم وقتی روی نرمافزارهایی که به شیوهی Interpretation کار میکنند اعمال میشوند، بحران میآفرینند. در آن زمان بخشی از پروداکشن باسلام هنوز مبتنی بر PHP و یک معماری Over-designed بود و دقیقا همین معماری پیچیده گلوگاه بود. پردازش دهها فایل و صدها Function call برای اجرای یک کوئری ساده و پاسخ به کاربر، ضرورتی نداشت. وقتی با ابزار Flame Graph هزینهی اجرای یک درخواست را تماشا میکردیم، میدیدیم چه ظرفیت بزرگی برای بهبود داریم. بنابرین «پردازش کمتر» یکی از کارهایی بود که باید میکردیم.
خوشبختانه در میکروسرویسهای جدید باسلام این Over-engineering را نداشتیم اما به هر حال بخشی از پروداکشن روی معماریهای قدیمی بود. پس تصمیم گرفتیم با تغییراتی، به جای حل مساله، صورت مساله را حذف کنیم. ما در سرویسهای قدیمی هر جا که میتوانستیم در سطح Web server از کش استفاده کردیم. یا اگر شدنی نبود در همان اولین خطوط پردازش درخواست (Request) کاربر در نرمافزار، او را به Cache حواله کردیم. اینطور به «پردازش کمتر» رسیدیم و CPU از شر پردازشهای بیهوده در امان میماند.
ما برای پردازش کمتر روی منابعی غیر از منابع خودمان هم میتوانستیم حساب کنیم: CDN. ما آن زمان از «CDN ستون» استفاده میکردیم و بار تصاویر را -که IO را بالا میبرند- به دوش آن گذاشته بودیم. اما علاوه بر تصاویر چیزهای دیگری هم بود که میتوانستیم با تنظیماتی ساده به CDN بسپریم: صفحات وب. البته لازم بود تغییراتی در ساختار صفحات بدهیم که بخشهای Dynamic -مثل سبد خرید و قیمت و موجودی- را تفکیک کنیم، و کردیم. باز هم چیزهای بیشتری برای سپردن به CDN وجود داشت: بسیاری از Endpoint های بکاند که از نوع Read بودند. استفادهکنندهاش هم Client های اندرویدی بودند و هم برخی صفحات وب. با این تنظیمات اپلیکیشن روی کاغذ میتوانست تا هزاران برابر بار را تحمل کند و منابعش را فقط به Manipulation (Create, Update) اختصاص بدهد! ولی خب موضوع روی کاغذ بود و در Load test های ما گاهی CDN آن انتظاری که داشتیم را تامین نمیکرد.
۴. پردازش بهینهتر
از لحاظ موضوعی خیلی بین پردازش کمتر و پردازش بهینهتر تفکیک نمیشود قائل شد؛ یک طیف هستند ولی منظورم از پردازش بهینهتر این است که پردازشهای غیرقابل حذف را دستکم بهینهتر انجام بدهیم. مثلا کوئریهای دیتابیس. این یک جملهی طلایی است که «همیشه باید بدانیم درون یک سیستم چطور کار میکند.» در این صورت میتوانیم درست از آن استفاده کنیم.
به یک مثال از پردازش بهینهتر کوئریهای دیتابیس اشاره میکنم. مثل هر کار دیگری که فرصتهای بهبود را بر اساس بزرگی مرتب میکنیم. دیتابیسهای رابطهای باسلام PostgreSQL هستند و ما از PgHero برای تحلیل بهرهوری آنها استفاده میکردیم. این ابزار ساده، تحلیل به درد بخوری از تعداد تکرار، مدت اجرا و در مجموع CPU Time ای که هر گروه کوئری میگیرد، ارائه میکند. فرضا شما متوجه میشوید کوئری نمایش سبد خرید پرتکرارترین کوئری است و هر بار اجرای آن میانگین ۴۷ms طول میکشد و مثلا ۱۰٪ پردازش دیتابیس را به خودش اختصاص داده. پس اگر شما این عدد را به ۱۰ms برسانید توانستهاید حدود ۸٪ کل پردازشهای دیتابیس را کاهش بدید که عدد بسیار بزرگی است. به همین ترتیب با یک کار یک روزه به راحتی ممکن است چند ده درصد از بار دیتابیس کم شود. طبیعتا هر چه جلوتر برویم این بهینهسازیها سختتر میشود.
برای بهینهسازی کوئریهای دیتابیس دمدستیترین کار آنالیز کردن کوئری است. با تحلیل مسیری که دیتابیس دارد دادهها را فراخوانی میکند، معمولا ایدههای خوبی برای تعریف و استفاده از Index های درست، به دست میآید. یک قدم مهمتر این است که مطمئن شویم کوئری دارد در هر گام واکشی اطلاعات، تنها اطلاعات ضروری را فرا میخواند (چون این اشتباه رایجی است که کوئریها را درگیر fetch کردن رکوردها غیرضروری میکنیم). از این بهتر و سختتر هم این است که جداول از ابتدا با یک نگاه همهجانبه -که Performance را هم در نظر داشته باشد- طراحی شده باشد یا با یک نگاه همه جانبه بازطراحی شود.
در مقیاس بالا دیتابیسی که بدون یک نگاه همه جانبه طراحی شده باشد میتواند پرهزینه و گلوگاه نرمافزار شود. ORMها پتانسیل ساختن کوئریهای غیربهینه دارند. Triggerها و Foreign Key ها میتوانند پردازشهای غیرضروری ایجاد کنند. Index های بلااستفاده یا غیرضروری یا تکراری میتوانند حجم و پردازش اضافه بار کنند. دخالت در مدیریت Lock های دیتابیس میتواند Dead-lock ایجاد کند. تعریف توابع و استفاده از آنها حساسیتهایی دارد. نداشتن استراتژی درست یا دستکاری ناآگاهانهی مدیریت Dead tuple ها در جداولی که تغییرات دادههایشان بسیار پربسامد است Bloat میسازد و نگهداری را سخت میکند. اینها چند نمونه از مراقبتهای کلیای است که معمولا این نوع دیتابیسها نیاز دارند و ما خوشبختانه بدهی زیادی در اینجا نداشتیم، چرا که در طول زمان معمولا این نکات را مورد توجه قرار میدادیم. اما به هر حال فرصتهای بهبودی بود و انجام دادیم.
در یکی از مشورتهایی که میگرفتیم ایدهی User-based partitioning دیتابیس برایمان جالب بود. موضوع این است که دیتابیسها در هر صورت حجیم میشوند و علاوه بر Partitioning هایی که معمولا دیتابیسها ارائه میدهند، یک Partitioning کاربر محور در سطح اپلیکیشن میتواند ایدهی درخشان و بسیار مفیدی باشد. البته که این ایده پیچیدگیهای زیادی داشت و گذاشتیم برای آینده.
۵. امنیت بیشتر
ما ریسکهای امنیتی شناخته شدهای با اهمیت پایین داشتیم که آنها را برای حل شدن لیست کرده بودیم. رفع اینها را اولویت دادیم. علاوه بر این با دو شرکت امنیتی برای آزمون نفوذ جعبه سیاه روی زیرساخت، Back-end و Client های باسلام قرارداد بستیم. ابزارهایی برای تستهای اتومیشن هم داشتیم که به صورت توزیع شده هر تیمی مسئولیت استفاده از خروجیهای آنها و رفع مشکلات را داشت.
یکی از کارهای مربوط به امنیت، Bypass کردن Firewall دیتاسنتر و استفاده از راهکار سختافزاری و نرمافزاری خودمان بود.
از قضا در همین روزهای آماده شدن برای تلویزیون، تجربهی یک حملهی امنیتی کوچک داشتیم. دو اشتباه دست به دست هم داد و این آسیبپذیری رقم خورد: یک اشتباه در بازنویسی یکی از میکروسرویسها و از کار افتادن Throttling Policy، و یک اشتباه بسیار قدیمی در Password Policy و وجود مجموعهای از پسوردهای ساده برای گروهی از غرفهداران. هکر کلاه سیاه با استفاده از این شرایط، اسکریپتی را اجرا کرد و از طریق چت باسلام، پیامهایی برای غرفهداران و مشتریان فرستاد. تجربهی این حملهی کوچک، بسیار ارزشمند بود و منجر به ارتقای ذهنیت تیم از اهمیت همهی روتینهای امنیتی و تقویت این روالها شد.
چطور این کارها را انجام دادیم؟
۳ ویژگی میتوانست شانس موفقیت این برنامه را کم کند.
- تعدد پروداکتها (دهها میکروسرویس)
- زمان کم
- تعدد تیمها و طول و عرض ساختار سازمانی (نزدیک به ده تیم پروداکتی که هر تیم یک EM داشت، در ۳ دامین مختلف که هر دامین یک EMD داشت و آنها به VP گزارش میدادند.)
مشکل اول را که با کوچک کردن مساله حل کردیم. اما مشکل زمان و ساختار پابرجا بود؛ اگر میخواستیم این برنامه را به شکلی که همیشه -در شرایط عادی- تفویض مسئولیت میشود به تیمها بسپاریم، زمان زیادی برای شکل گرفتن همذهنی سپری میشد. بنابرین به یک طراحی متفاوت نیاز داشتیم.
برای همذهنی سریع، جلسهای با همهی EMDها و EMها گذاشتیم، شرایط جدید را بیان کردیم، محدودیت زمان و اهمیت هر ساعت را گفتیم، روی اصل خودبسندگی تاکید کردیم و به طبع توقف برنامههای قبلی که با برنامهی جدید همپوشان نیستند را اعلام کردیم (مگر این که افراد امکانی برای مشارکت در برنامهی جدید نداشته باشند. برای مثال کسی که مشغول توسعهی مدلهای هوش مصنوعی است، ممکن است نقش خاصی نتواند برای این برنامه ایفا کند). بعد از این همذهنی، استراتژی کلی برای آمادگی را شرح دادیم و در یک دیالوگ جمعی، شروع به طراحی جزئیات استراتژی و جزئیات اجرایی کردیم.
یکی از مهمترین بخشهای شیوهی اجرای این کار این بود که جلسات Daily تنظیم کردیم و هر روز خیلی کوتاه همهی EMD ها دور هم جمع میشدند و گزارش پیشرفت کارها را میدادند، اگر مشکلی بود با هم حل میکردند و اگر به ایده و مشورتی نیاز داشتند، اشتراک تجربه میکردند. برای مثال در همین جلسات راهکار Load Test سرویسها از طریق پروداکت چندمنظورهی KDP باسلام (که بعدها دربارهی آن خواهید شنید) بین افراد به اشتراک گذاشته شد و روی تجربههای Scale کردن یک میکروسرویس نکات ریز و درشت زیادی رد و بدل شد که به تسریع این برنامه کمک بسیار خوبی میکرد. بعدها که همذهنی تیم بیشتر شد، این جلسات به یک روز در میان و کمتر کاهش پیدا کرد.
به این صورت کل این کار به صورت توزیع شده با موفقیت در شرکت اجرا شد.
نتایج
تیم مهندسی باسلام با استراتژی ۵ بخشیای که داشت و با تکرار Load Test ها در نهایت به این نتایج رسید:
- ظرفیت تحمل بار ۲۰ تا ۱۰۰ برابری -و بیشتر- در میکروسرویسهای مختلف
- بهبود ۲.۶ برابری شاخص LCP (از ۷.۶ ثانیه به ۲ ثانیه)
- رفع SPoFها
- توان حفظ پایداری نرمافزار در ترافیک بالا با مدیریت Degradation
- ارتقای امنیت باسلام
تبلیغات تلویزیونی باسلام بدون کوچکترین مشکلی در پایداری نرمافزار اجرا شد. بعد از این کمپین تلویزیونی، میانگین ترافیک باسلام بیش از ده برابر شد؛ کمتر از چیزی بود که فکر میکردیم ولی تلاش برای این آمادگی، نگرش تیم مهندسی و حتی محصول را ارتقا داد؛ «نگرش و فرهنگ کیفیتگرایی مفید، اما نه چندان گران قیمت در نرمافزار». ارتقای کیفیت نرمافزار به طور ضمنی روی SEO باسلام نیز تاثیرات درخشانی گذاشت.
سپاس از دوستانی که نقش داشتند
علاوه بر همهی مهندسان باسلام که با همآهنگی در اجرای مجموعهی این صدها تغییر، نقشآفرین بودند، از تجربهی چند مشاور عزیز هم استفاده کردیم و نکات ارزشمندی یاد گرفتیم که به این بهانه، بدون ترتیب خاصی از این دوستان بابت اشتراک دانششان بسیار تشکر میکنیم؛ سید جمال پیشوایی مدیر فنی شرکت اعوان، کیانوش مختاریان مهندس ارشد Google Ads، مجید گلشادی مدیر مهندسی Delivery Hero، طه جهانگیر مدیر فنی شرکت سبز سیستم، سید مهران خلدی مدیر فنی شرکت همروش.
۲ شهریور ۱۴۰۲
مطلبی دیگر از این انتشارات
از خاکستر بحران تا نقشهی آینده: نقشه مناطق بمباران شده ایران
مطلبی دیگر از این انتشارات
تجربه ایجاد تیم تست: باسلام چطور تیم تستدار شد؟
مطلبی دیگر از این انتشارات
چگونه با استفاده از Metabase SDK و FastAPI، دسترسی امن و محدود به دادههای داشبوردها ایجاد کردیم؟